High-availability ad absurdum - instant messenger cluster using DRBD and Finch (Pidgin)
It is often unjustifiable said that implementing high-availability under Linux is way too complex. Of course you will have to be patient while spending some time in learning the required basics - but all this is feasible for an experienced administrator (or someone who wants to be such an administrator some day). This example shows how easy a simple 2-node cluster can be built.
When it is necessary to keep data synchronous between multiple hosts, implementing a DRBD (Distributed Replicated Block Device) might be the most elegant and easiest solution.
You can attach a dedicated LUN to your servers and file the application (which shall be protected using the cluster) on it. In combination with heartbeat, Pacemaker or similiar HA solutions, DRBD is the core of high-available Linux applications.
Ths concept is simple and brilliant at the same time - there are no bounds to the wide range of possibilities like the following slightly escapist example shows.
High-availability ad absurdum
If you're communicating online you surely know plenty of instant messengers, including the three well-known ones Skype, ICQ and Jabber. To use these protocols also under Linux there are multiprotocol messengers like Pidgin. There is a special version of Pidgin which uses a curses command-line instead of a graphical user interface - Finch. This tools is used as mission-critical application in an active/passive heartbeat cluster in this example. The result is a high-available instant messenger that automatically fails over to another node (in another fire area) without loosing its configuration and data. I'm sure that some readers will now start thinking about how they could live without such an application before. 🙂
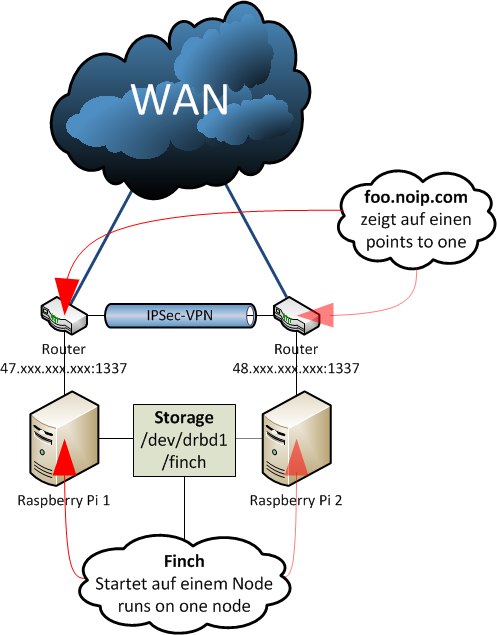
In this example two Raspberry Pi are used behind two conventional DSL routers. Thanks to a port forwarding (which has to be created equivalently on both routers) it is possible to access those hosts using SSH from "out there" (WAN) - you might want to choose a more secure port instead of the standard port 22. Using a tool named GNU screen a started terminal session running finch can be continued at any time - using this you have access to your personal "chat shell" from every host connected to the internet. Both routers are connected to a IPsec VPN in this example. The Raspberry Pi are able to ping and communicate with each other using a secured tunnel - even though they are in two different network segments.
Using a tool called heartbeat the nodes are checked for availability later - for this mechanism the VPN between the routers is used - another possibility is to implement a point-to-point VPN between the nodes (e.g. using OpenVPN). If a cluster node fails, the other node is informed about the failure and takes over access to the shared storage (discussed later!) and restarts the application as soon as possible (active/passive cluster principle).
Beside the two Raspberry Pi two USB sticks are needed as replicated block device - DRBD doesn't like pseudo-devices like files created with dd. Application configuration and protocol files of Finch are saved on this "cluster disk" so that the application always has the same data - independent of the node it's currently running on.
Design and network
For this example I registered a NoIP hostname - after registration the dynamic hostname can be updated using a special Linux utility provided by NoIP. This tool needs to be compiled and installed on the two Raspberry Pi:
1both-nodes # apt-get install gcc curl
2both-nodes # wget http://www.no-ip.com/client/linux/noip-duc-linux.tar.gz
3both-nodes # tar xfz noip-duc-linux.tar.gz
4both-nodes # cd noip-*
5both-nodes # make && make install
6...
7Please enter the login/email string for no-ip.com
8Please enter the password for user '...'
9...
10Please enter an update interval:[30] 44640
11...
By default, the NoIP client is running in the background - and that's exactly what we don't want in this cluster setup. The IP needs to be updated in case of a failover performed by heartbeat. If the applications fails over from one node to another the hostname needs to be updated to ensure that access to the correct node is possible. Testing the compiled tool is necessary to guarantee that it is working as expected:
1any-node # /usr/local/bin/noip2 -i $(curl --silent http://icanhazip.com)
2any-node # ping chat.noip.com
Additional packages for drbd and heartbeat have to be installed:
both-nodes # apt-get install drbd8-utils heartbeat
DRBD
Before the shared cluster storage is created, it is necessary to ensure that the both nodes are able to communicate with each other. It is recommended to create a local entry in the /etc/hosts file (to be independent of a possibly faulty DNS service) - even if you have a working DNS. After that pinging the nodes has to work:
1both-nodes # vi /etc/hosts
2....
3
4192.168.1.2 hostA.fqdn.dom hostA
5192.168.2.2 hostB.fqdn.dom hostB
6
7ESC ZZ
8
9node-a # ping hostA
10node-a # ping hostB
11node-b # ping hostA
12node-b # ping hostB
The connected USB sticks are re-partitioned (existing partitions are removed) - a Linux partition (type 83) is created. After that the DRBD configuration file is altered:
1both-nodes # fdisk /dev/sda < < EOF
2d
34
4d
53
6d
72
8d
91
10
11n
12p
131
14
15w
16EOF
17
18both-nodes # cp /etc/drbd.conf /etc/drbd.conf.initial
19both-nodes # vim /etc/drbd.conf
20...
21resource drbd1 {
22 protocol C;
23
24 syncer {
25 rate 75K;
26 al-extents 257;
27 }
28 on hostA.fqdn.dom {
29 device /dev/drbd1;
30 disk /dev/sda1;
31 address 192.168.1.2:7789;
32 meta-disk internal;
33 }
34 on hostA.fqdn.dom {
35 device /dev/drbd1;
36 disk /dev/sda1;
37 address 192.168.2.2:7789;
38 meta-disk internal;
39 }
40
41}
A volume drbd1 which is respectively synchronized to the device /dev/sda1 on the nodes hostA.fqdn.com and hostB.fqdn.com is defined.
The following line is very important:
1rate 75K;
This line defines the maximal synchronization rate in byte per second - in this case 75 KB/s. The synchronization is speed depends on different factors and shall be choosed carefully. For example, the defined speed rate should not exceed the maximal speed provided by the used storage medium. If DRBD and application use the same network segment (it is better to have an additional network for DRBD) you will have to consider the needs of the other network traffic.
A rule of thumb is to set the value of syncer rate to the 0.3 times of the effective network bandwidth - there is an example in the drbd handbook:
110 MB/s bandwidth * 0.3 = 33 MB/s
1...
2syncer rate = 33M;
If the network isn't able to provide the definied maximal speed the speed is automatically throttled. More information about synchronization can be found in the handbook of DRBD: [click me!].
Afterwards the volume is created, activated and formatted on one node. After this, the new volume is mounted:
1node-a # drbdadm create-md drbd1
2
3==> This might destroy existing data! < ==
4Do you want to proceed? [need to type 'yes' to confirm] yes ...
5
6node-a # drbdadm up drbd1
7node-a # drbdadm primary drbd1
8node-a # mkfs.ext4 /dev/drbd1
9both-nodes # mkdir /finch
10node-a # mount /dev/drbd1 /finch
The changes are catched up on the other node - this can take some time for the first initialization (time for a coffee!). In my case the initialization of a 256 MB USB stick took about one hour using a VPN with 75 kbit/s upload rate. The status can be seen by reading the file /proc/drbd:
1node-b # drbdadm connect drbd1
2node-b # uptime
3 16:40:30 up 2:08, 1 user, load average: 0,20, 0,16, 0,10
4
5both-nodes # cat /proc/drbd
6version: 8.3.13 (api:88/proto:86-96)
7srcversion: A9694A3AC4D985F53813A23
8
9 1: cs:SyncTarget ro:Secondary/Primary ds:Inconsistent/UpToDate C r-----
10 ns:0 nr:104320 dw:104320 dr:0 al:0 bm:6 lo:1 pe:2321 ua:0 ap:0 ep:1 wo:f oos:148564
11 [=======>............] sync'ed: 42.0% (148564/252884)K
12 finish: 0:32:11 speed: 64 (24) want: 71,680 K/sec
Once the synchronization is finished, it is necessary to check whether changes are replicated and roles can be switched. To check this, the following tasks are executed:
- creating a file on the primary DRBD node, creating MD5 sum
- unmounting the file system, downgrading to secondary role
- upgrading the second DRBD node, mounting file system
- find file, check MD5 sum
- delete file and create another file
- resetting the roles
In this example only the primary node is able to access the volume exclusively, the secondary node has no access to the volume. If you want both nodes to be able to access the volume (e.g. if you're implementing an active/active cluster) ext4 is not the file system to choose. In such a scenario you will have to choose a cluster filesystem like GFS or OCFS2. These filesystems offer special locking mechanisms to manage the access to the volume for the individual nodes.
1node-a # dd if=/dev/zero of=/finch/bla.bin bs=1024k count=1
2node-a # md5sum /finch/bla.bin > /finch/bla.bin.md5sum
3node-a # umount /finch
4node-a # drbdadm secondary drbd1
5
6node-b # drbdadm primary drbd1
7node-b # mount /dev/drbd1 /finch
8node-b # ls /finch
9lost+found bla.bin bla.bin.md5sum
10node-b # md5sum -c /finch/bla.bin.md5sum
11/finch/bla.bin: OK
12node-b # rm /finch/bla.bin*
13node-b # dd if=/dev/zero of=/finch/foo.bin bs=1024k count=1
14node-b # md5sum /finch/foo.bin > /finch/foo.bin.md5sum
15node-b # umount /finch
16node-b # drbdadm secondary drbd1
17
18node-a # drbdadm primary drbd1
19node-a # mount /dev/drbd1 /finch
20node-a # ls /finch
21lost+found foo.bin foo.bin.md5sum
22node-a # md5sum -c /finch/foo.bin.md5sum
23/finch/foo.bin: OK
Seems to work like a charm! 🙂
Finch
Like mentioned before, the multi-protocol messenger Finch (Pidgin) is used as mission-critical application in this scenario. It is a proper behaviour to provide a dedicated service user and a unique UID in order to ensure that the application can be started in a script executed by heartbeat on a node afterwards. To start the tool in the background and enable it to be access remotely, GNU Screen is used as terminal multiplexer.
1both-nodes # apt-get install screen finch
2both-nodes # useradd -u 1337 -m -d /finch/home su-finch
3both-nodes # gpasswd -a su-finch tty
4both-nodes # passwd su-finch
Adding the user su-finch to the group tty is necessary to ensure that GNU screen is able to access the terminal if it is started using the su mechanism.
First of all finch can be configured to use an instant messenger account:
1node-a # su - su-finch
2node-a # screen
3node-a # finch
If you have used Pidgin before, you might recognize the buddy list and chat windows.
Windows are switched using key combinations - in combination with GNU screen it is also possible to use mouse navigation. Some important pre-defined key combinations:
- next window: ALT + N
- previous window: ALT + P
- close selected window: ALT + C
- open context menu: F11
- open action menu: ALT + A
- open menu of current window: CTRL + P
heartbeat - computer, are you still alive?
heartbeat is - as its name implies - primarly used for ensuring the availability of the particular cluster nodes. The tool communicates constantly with neighbor cluster nodes using a encrypted tunnel and is able to react fast on failures. If such a failure occurs. pre-defined scripts are executed to compensate the failure. In this example two cluster resources are restarted on the next available node: the shared DRBD storage and the service finch.

It might be necessary in a cluster to ensure that faulty nodes wont continue serving their services (depending on size and application) to avoid data corruption and service misfunction. This mechanism is called STONITH (Shoot the other node in the head). There are plenty of interfaces which can be used to make sure that the faulty cluster node "keeps down" - for example:
- servers remote interface (iLO, DRAC, LOM,...)
- UPS the server is connected to
- PDU (Power Distribution Unit) the cluster node is consuming power from
- blade enclosure management interface
If STONITH is not used, data corruption and application failure might occure in extreme cases when both cluster nodes are hold that they are the only active node and run the application (e.g. because of a network failure). Of course STONITH can also be implemented under Linux - amongst others using heartbeat or Pacemaker. But in this example, this would go beyond the scope of this well-arranged scenario. 😉
Applications can be served in a cluster using heartbeat very easy because conventional init scripts are used for service management. In an ideal case symbolic links can be used to integrate a service into a cluster.
In this example an used-defined init script which starts Finch and updates the NoIP hostname is created.
First of all, a cluster-wide configuration file (/etc/ha.d/ha.cf) is created. This configuration file includes essential parameters like log files and thresholds:
1node-a # vi /etc/ha.d/ha.cf
2debugfile /var/log/ha-debug
3logfile /var/log/ha-log
4logfacility local0
5keepalive 10
6deadtime 30
7warntime 20
8initdead 60
9ucast eth0 192.168.2.2
10udpport 694
11auto_failback off
12node hostA.fqdn.dom
13node hostB.fqdn.dom
14
15ESC ZZ
16
17node-b # vi /etc/ha.d/ha.cf
18...
19ucast eth0 192.168.1.2
20...
21
22ESC ZZ
The file differs between the nodes in one line (ucast) - the appropriate IP address of the other node is used.
Some explanations of the individual parameters:
debugfile/logfile/logfacility- debug- and generic log, used Syslog facilitykeepalive- time frame keepalives are sentwarntime- time frame nodes are threaten to faildeadtime- time frame a node seems to be deadinitdead- time frame a node is removed from the clusterucast- IP address, unicast heartbeat packages are sent toudpport- UDP portauto_failback- defines whether failed cluster nodes shall receive their former resources (if they were preferred nodes for particular resources)node- defines the given cluster nodes
Because the cluster communication is done encrypted, a file /etc/ha.d/authkeys has to be created on both nodes.:
1both-nodes # vi /etc/ha.d/authkeys
2auth 1
31 sha1 verylongandultrasavepasswordphrase08151337666
Afterwards the cluster resources are mentioned in the file /etc/ha.d/haresources:
1both-nodes # vi /etc/ha.d/haresources
2hostA.fqdn.dom
3hostB.fqdn.dom drbddisk::drbd1 Filesystem::/dev/drbd1::/finch::ext4 finch
This file lists all available cluster nodes and - separated using a tab - preferred resources. In this example there are two hosts, the second one is the primary cluster node for the following resources:
- exclusive used DRBD volume
drbd1 ext4file system on/dev/drbd1, mounted as/finch- the service
finch(/etc/init.d/finch)
This means: if both cluster nodes are available, the above mentioned resources are always running on node 2 (hostB.fqdn.dom). If this node fails, the resouces are restarted on node 1 (hostA.fqdn.dom). Automatic resource restarting after the failed cluster node becomes available again is avoided because of the setting "auto_failback off" (in the file /etc/ha.d/ha.cf).
At last the init script for starting and stopping the finch service needs to be created - like other init scripts, this script is created under /etc/init.d/finch:
1# vi /etc/init.d/finch
2#!/bin/bash
3#
4# finch Startup script for finch including noip update
5#
6
7start() {
8 /usr/local/bin/noip2 -i $(curl --silent http://icanhazip.com) >/dev/null 2>&1
9 chmod g+rw $(tty)
10 su -c "screen -d -m" su-finch
11 RESULT=$?
12 return $RESULT
13}
14stop() {
15 /usr/bin/killall -u su-finch
16 RESULT=$?
17 return $RESULT
18}
19status() {
20 su -c "screen -ls" su-finch
21 cat /proc/drbd
22 dig +short foo.noip.com
23 RESULT=$?
24 return $RESULT
25}
26
27case "$1" in
28 start)
29 start
30 ;;
31 stop)
32 stop
33 ;;
34 status)
35 status
36 ;;
37 *)
38 echo $"Usage: finch {start|stop|status}"
39 exit 1
40esac
41
42exit $RESULT
This init script recognizes the parameters start, stop and status - it might almost be LSB-compatible. 🙂
Depending on the parameter a GNU screen sessing is started or stopped using the user account of su-finch (service user) - the status parameter lists current DRBD and IP mappings including current sessions.
Whenever heartbeat starts or stops finch ressources, this script is used.
Function test
Ok, this sounds nice - but is it working at all?
Of course it is - the following video shows a demonstration of cluster failover:
😄
Monitoring

It is a proper behaviour to monitor a mission-criticial application. Beside the availability of the appropriate cluster nodes, the state of DRBD and heartbeat is of note, too. While the availability of the heartbeat service can be checked easily using the Nagios/Icinga plugin check_procs, there is a special shell script for DRBD (free to download) on the website MonitoringExchange: [click me!]
This script can be included into Nagios or Icinga and used easily, e.g. in this example on a passive Icinga instance:
1# cat /etc/icinga/commands.cfg
2...
3# 'check_drbd' command definition
4define command{
5 command_name check_drbd
6 command_line $USER2$/check_drbd -d $ARG1$ -e "Connected" -o "UpToDate" -w "SyncingAll" -c "Inconsistent"
7}
8
9# cat /etc/icinga/objects/hostA.cfg
10...
11define service{
12 use generic-service
13 host_name hostA
14 service_description HW: drbd1
15 check_command check_drbd!1
16 }
In this example the available of the DRBD volume /dev/drbd1 is checked. If the script answer (based on the content of the file /proc/drbd) is not "Connected/UpToDate", a failure has occured. If the volume is synchronizing (SyncingAll), Nagios/Icinga reports a warning - an inconsistent volume (Inconsistent) forces a critical event.
Conclusion
It is no doubt that this scenario is rather escapist than realistic - it is just for fun. I just wanted to show how easy implementing high-availability under Linux can be. There are many ways to get it working - heartbeat and DRBD is only one of many HA constellations. The topic isn't that complex as often unjustifitable said. In the first step it is irrelevant whether a database or an instant messenger is "clustered" using heartbeat - the implementation effort is manageable.
heartbeat is said to be obsolete - Pacemaker and OpenAIS/Corosync are two more modern utitilies that can be used in combination with DRBD to implement more complex and larger HA scenarios.
As a matter of principle hardware components should be designed redundant before implementing software HA solutions. In this example, there are some architecture mistakes that should be fixed in case of practical application:
- no dedicated network for node communication (heartbeat network)
- no redundant storage for cluster storage (RAID volume)
- network adapters are not redundant (no double NICs/teaming or appropriate connected switches; LACP?)
- no redundant power supply
At least dedicaded fire areas had been chosen for this scenario (the Raspberry Pi are located in two different flats)! 🙂
However - if you're interested in keeping your instant messenger redundant, you know how to do this now. 😉