Hochverfügbarkeit ad absurdum - Instant Messenger-Cluster mit DRBD und Finch (Pidgin)
Hochverfügbarkeit unter Linux wird oftmals unberechtigterweise für ein bodenloses Fass gehalten. Zugegebenermaßen bedarf der Einstieg einiger Geduld und verlangt auch Einlesungsvermögen - es ist allerdings machbar und für jeden halbwegs routinierten Administrator (oder jemanden, der es mal sein will) ein stemmbares Hindernis. Dieses Beispiel soll zeigen, wie simpel der Aufbau eines einfachen 2-Node-Clusters sein kann.
Wenn es darum geht, Daten zwischen mehreren Hosts stets synchron zu halten, ist die Verwendung eines DRBDs (Distributed Replicated Block Device) meistens die eleganteste und einfachste Lösung.
So kann man seine Server beispielsweise mit dedizierten LUNs ausstatten und auf diesen die durch den späteren Cluster zu schützende Applikationen ablegen. In Kombination mit heartbeat, Pacemaker oder ähnlichen HA-Lösungen ergibt DRBD das Herzstück für hochverfügbare Linux-Applikationen.
Das Konzept ist simpel und genial zugleich - den Möglichkeiten sind hier keine Grenzen gesetzt, wie das folgende, etwas realitätsferne, Beispiel zeigt.
Hochverfügbarkeit ad absurdum
Wer gerne online soziale Kontakte pflegt, kennt die verschiedensten Instant-Messenger, von denen Skype, ICQ und Jabber nur drei prominente Vertreter sind. Um diese Protokolle auch unter Linux zu verwenden, gibt es Multiprotokoll-Messenger, wie beispielsweise Pidgin. Von Pidgin existiert eine Variation, die keine grafische Oberfläche verwendet und stattdessen auf eine curses-Textoberfläche zurückgreift - Finch. Dieses Tool dient hier als unternehmenskritische Applikation, die mithilfe von heartbeat später in einem Active/Passive Cluster betrieben wird. Das Resultat ist ein hochverfügbarer Instant-Messenger, der im Fehlerfall auf einen zweiten Node in einem anderen Brandabschnitt wechselt - ohne dabei seine Konfiguration und Protokolle zu verlieren. Sicherlich werden sich jetzt viele Leser fragen, wie sie bisher ohne eine solche Applikation leben konnten. 🙂
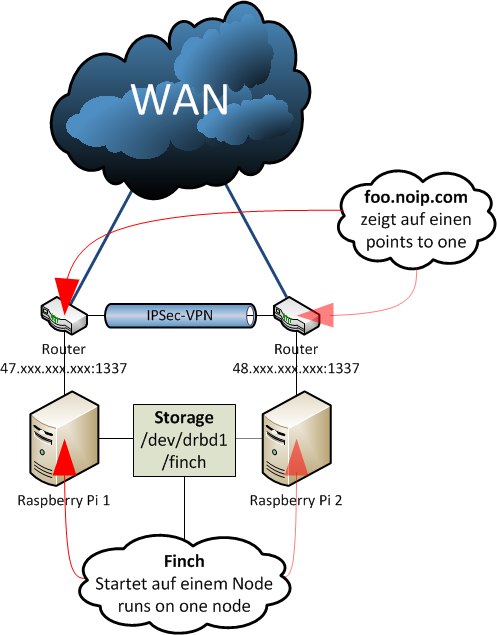
In diesem Beispiel gibt es zwei Raspberry Pi, die hinter jeweils einem herkömmlichen DSL-Router betrieben werden. Über eine Portfreigabe, die auf beiden Routern äquivalent einzurichten ist, ist ein Zugriff von "außen" (WAN) über SSH auf den Raspberry Pi möglich - idealerweise nimmt man hier jedoch nicht den Standardport 22. Über ein Tool namens GNU screen kann eine Terminal-Sitzung mit ausgeführten finch jederzeit fortgesetzt werden - so hat man von jedem Host mit Internetverbindung Zugriff auf die "Chat-Shell". Die beiden Router sind in diesem Beispiel mit einem IPSec-VPN verbunden, die beiden Raspberry Pi können sich also anpingen und über einen verschlüsselten Kanal kommunizieren, obwohl sie sich in unterschiedlichen, voneinander getrennten, Netzwerksegmenten befinden.
Mithilfe eines Tools namens heartbeat wird später eine gegenseitige Überprüfung auf Verfügbarkeit durchgeführt (daher das VPN zwischen den Routern; die Clusternodes müssen einander anpingen können - eine andere Möglichkeit wäre ein Point-to-Point-VPN, beispielsweise mittels OpenVPN). Fällt ein Clusternode aus, bekommt dies der andere Node mit, übernimmt den Zugriff auf die gemeinsame Speicherressource (dazu später mehr!) und startet die Anwendung schnellstmöglich neu (entspricht dem Active/Passive Cluster-Prinzip).
Neben den zwei Raspberry Pi werden noch zwei USB-Sticks benötigt, die in diesem Aufbau das zu replizierende Blockgerät darstellen - DRBD mag keine Pseudo-devices, wie beispielsweise mit dd angelegte Dateien. Auf dieser "Cluster-Disk" werden die Konfigurations- und Protokolldateien von Finch gespeichert. So verfügt die Applikation stets über die selben Daten - unabhängig davon, wo sie gerade ausgeführt wird.
Aufbau und Netzwerk
Für dieses Beispiel habe ich mir einen NoIP-Hostname zugelegt - nach der Registrierung kann die mit dem dynamischen Hostname verbundene IP über ein NoIP-eigenes Linux-Utility aktualisiert werden. Dieses muss auf den beiden Raspberry Pi übersetzt und installiert werden:
1both-nodes # apt-get install gcc curl
2both-nodes # wget http://www.no-ip.com/client/linux/noip-duc-linux.tar.gz
3both-nodes # tar xfz noip-duc-linux.tar.gz
4both-nodes # cd noip-*
5both-nodes # make && make install
6...
7Please enter the login/email string for no-ip.com
8Please enter the password for user '...'
9...
10Please enter an update interval:[30] 44640
11...
Standardmäßig läuft der NoIP-Client im Hintergrund - genau das wollen wir in diesem Cluster-Setup jedoch nicht. Über heartbeat erfolgt später ein geskriptetes Update im Falle eines Failovers. Wenn die Anwendung also von einem Node zum anderen wechselt, wird die IP-Adresse, mit der auf die Chat-Shell zugegriffen wird, aktualsiert. Durch eine manuelle Ausführung kann sichergestellt werden, dass das Tool ordnungsgemäß funktioniert:
1any-node # /usr/local/bin/noip2 -i $(curl --silent http://icanhazip.com)
2any-node # ping chat.noip.com
Für den späteren Clusterbetrieb müssen noch Software-Pakete für drbd und heartbeat installiert werden:
1both-nodes # apt-get install drbd8-utils heartbeat
DRBD
Bevor der gemeinsame Clusterspeicher eingerichtet wird, ist es notwendig sicherzustellen, dass die beiden Nodes einander finden. Auch bei funktionierendem DNS sollte man hierfür immer einen lokalen Eintrag in der /etc/hosts vornehmen (um unabhängig von einem evtl. anfälligen DNS-Service zu sein) und die Nodes anpingen:
1both-nodes # vi /etc/hosts
2....
3
4192.168.1.2 hostA.fqdn.dom hostA
5192.168.2.2 hostB.fqdn.dom hostB
6
7ESC ZZ
8
9node-a # ping hostA
10node-a # ping hostB
11node-b # ping hostA
12node-b # ping hostB
Die beiden angeschlossenen USB-Sticks werden neu partitioniert (vorhandene Partitionen werden entfernt), sie erhalten eine Linux-Partition (Typ 83). Anschließend wird die DRBD-Konfigurationsdatei angepasst:
1both-nodes # fdisk /dev/sda << EOF
2d
34
4d
53
6d
72
8d
91
10
11n
12p
131
14
15w
16EOF
17
18both-nodes # cp /etc/drbd.conf /etc/drbd.conf.initial
19both-nodes # eoe /etc/drbd.conf
20...
21resource drbd1 {
22 protocol C;
23
24 syncer {
25 rate 75K;
26 al-extents 257;
27 }
28 on hostA.fqdn.dom {
29 device /dev/drbd1;
30 disk /dev/sda1;
31 address 192.168.1.2:7789;
32 meta-disk internal;
33 }
34 on hostA.fqdn.dom {
35 device /dev/drbd1;
36 disk /dev/sda1;
37 address 192.168.2.2:7789;
38 meta-disk internal;
39 }
40
41}
Definiert wird hier ein Volume drbd1, welches auf den beiden Nodes hostA.fqdn.com und hostB.fqdn.com jeweils auf dem Gerät /dev/sda1 synchronisiert wird.
Sehr wichtig ist auch folgende Zeile:
1rate 75K;
Sie definiert die maximale Synchronisierungsrate in Byte pro Sekunde, hier 75 KB/s. Die Synchronisierungsgeschwindigkeit ist von vielen Faktoren abhängig und sollte sorgfältig ausgewählt werden. Die Geschwindigkeit sollte beispielsweise nicht höher sein, als der verwendete Speicher es zulässt. Wenn für DRBD und die Applikation das gleiche Netzwerksegment verwendet wird (idealerweise hat man für DRBD ein eigenes Netzwerk), muss auf den üblichen Netzwerktraffic Rücksicht genommen werden.
Eine Faustregel besagt, den Wert der Syncer rate auf das 0.3-fache der effektiv verfügbaren Bandbreite zu setzen - ein Beispiel findet sich im Handbuch von DRBD:
110 MB/s Bandbreite * 0.3 = 33 MB/s
1...
2syncer rate = 33M;
Lässt das Netzwerk die definierte Maximalgeschwindigkeit nicht zu, wird automatisch gedrosselt. Mehr Informationen zur Synchronisation finden sich im Handbuch von DRBD: [klick mich!].
Anschließend wird einem Node das Volume angelegt, aktiviert und formattiert. Danach wird das neue Volume eingehängt:
1node-a # drbdadm create-md drbd1
2
3==> This might destroy existing data! <==
4Do you want to proceed? [need to type 'yes' to confirm] yes ...
5
6node-a # drbdadm up drbd1
7node-a # drbdadm primary drbd1
8node-a # mkfs.ext4 /dev/drbd1
9both-nodes # mkdir /finch
10node-a # mount /dev/drbd1 /finch
Auf dem anderen Node werden die Änderungen nachgezogen, was bei der initialien Synchronisierung schon etwas dauern kann (Zeit für einen Kaffee!) - in meinem Beispiel dauerte die Initialisierung eines 256 MB USB-Sticks über VPN bei 75 kbit/s Upload ca. eine Stunde - der Status kann über die Datei /proc/drbd eingesehen werden:
1node-b # drbdadm connect drbd1
2node-b # uptime
3 16:40:30 up 2:08, 1 user, load average: 0,20, 0,16, 0,10
4
5both-nodes # cat /proc/drbd
6version: 8.3.13 (api:88/proto:86-96)
7srcversion: A9694A3AC4D985F53813A23
8
9 1: cs:SyncTarget ro:Secondary/Primary ds:Inconsistent/UpToDate C r-----
10 ns:0 nr:104320 dw:104320 dr:0 al:0 bm:6 lo:1 pe:2321 ua:0 ap:0 ep:1 wo:f oos:148564
11 [=======>............] sync'ed: 42.0% (148564/252884)K
12 finish: 0:32:11 speed: 64 (24) want: 71,680 K/sec
Sobald die Synchronisation abgeschlossen ist, sollte überprüft werden, ob Änderungen repliziert und Rollen problemslos gewechselt werden. Dazu wird folgendes ausgeführt:
- Erstellen einer Datei auf dem primären DRBD-Node, MD5-Summe erstellen
- Aushängen des Dateisystems, auf sekundäre Rolle herabstufen
- Heraufstufen des zweiten DRBD-Nodes, Dateisystem einhängen
- Datei finden, MD5-Prüfsumme überprüfen
- Datei löschen und weitere anlegen
- Zurückstufen der Rollen
In diesem Beispiel kann immer nur der primäre Node exklusiv auf das Volume zugreifen, der sekundäre Node hat keinen Zugriff auf das Volume. Soll ein Volume von beiden Nodes zeitgleich aktiv eingesetzt werden können (beispielsweise, weil ein Active/Active Cluster implementiert wird), ist ext4 hier das falsche Dateisystem. In einem solchen Fall muss ein Cluster-Dateisystem, wie GFS oder OCFS2, verwendet werden. Diese Dateisysteme bieten spezielle Locking-Mechanismen, die die Zugriffe der einzelnen Nodes auf das Volume regeln.
1node-a # dd if=/dev/zero of=/finch/bla.bin bs=1024k count=1
2node-a # md5sum /finch/bla.bin > /finch/bla.bin.md5sum
3node-a # umount /finch
4node-a # drbdadm secondary drbd1
5
6node-b # drbdadm primary drbd1
7node-b # mount /dev/drbd1 /finch
8node-b # ls /finch
9lost+found bla.bin bla.bin.md5sum
10node-b # md5sum -c /finch/bla.bin.md5sum
11/finch/bla.bin: OK
12node-b # rm /finch/bla.bin*
13node-b # dd if=/dev/zero of=/finch/foo.bin bs=1024k count=1
14node-b # md5sum /finch/foo.bin > /finch/foo.bin.md5sum
15node-b # umount /finch
16node-b # drbdadm secondary drbd1
17
18node-a # drbdadm primary drbd1
19node-a # mount /dev/drbd1 /finch
20node-a # ls /finch
21lost+found foo.bin foo.bin.md5sum
22node-a # md5sum -c /finch/foo.bin.md5sum
23/finch/foo.bin: OK
Scheint wunderbar zu funktionieren! 🙂
Finch
Wie vorhin erwähnt, dient der Multiprotokoll-Messenger Finch (Pidgin) in diesem Fall als unternehmenskritische Applikation. Wie es sich für eine solche Applikation gehört, bekommt sie einen Serviceuser mit einer einheitlichen UID verpasst, damit das Tool nachher über heartbeat auf den Nodes geskriptet gestartet werden kann. Hierzu wird GNU Screen als Terminal-Multiplexer verwendet, um das Tool im Hintergrund zu starten und die Möglichkeit zu schaffen, remote auf die Sitzung zuzugreifen.
1both-nodes # apt-get install screen finch
2both-nodes # useradd -u 1337 -m -d /finch/home su-finch
3both-nodes # gpasswd -a su-finch tty
4both-nodes # passwd su-finch
Die Hinzufügen von su-finch in die Gruppe tty ist übrigens notwendig, damit GNU screen später auf das Terminal zugreifen kann, wenn es über den su-Mechanismus gestartet wird.
Vorab kann man finch allerdings schon mal konfigurieren und ein Instant Messenger-Konto seiner Wahl hinzufügen:
1node-a # su - su-finch
2node-a # screen
3node-a # finch
Wer schon einmal Pidgin benutzt hat, wird die Buddy-Liste und Chat-Fenster wiedererkennen.
Die Fenster werden in der Regel mittels Tastenkombinationen gewechselt, in Kombination mit GNU screen besteht jedoch auch die Möglichkeit der Maussteuerung. Einige wichtige vordefinierte Tastenkombinationen:
- nächstes Fenster: ALT + N
- vorheriges Fenster: ALT + P
- markiertes Fenster schließen: ALT + C
- Kontextmenü aufrufen: F11
- Aktionsmenü aufrufen: ALT + A
- Menü des aktuellen Fensters aufrufen: STRG + P
heartbeat - Computer, lebst Du noch?
heartbeat dient primär, wie der Name vermuten lässt, zur Kommunikation von Clusternodes, um deren Verfügbarkeit zu gewährleisten. Das Tool kommuniziert mit benachbarten Clusternodes regelmäßig über einen verschlüsselten Tunnel und kann so schnell auf Ausfälle reagieren. Tritt ein solcher Ausfall ein, starten vorher definierte Skripte, um diesen zu kompensieren. In diesem Beispiel werden zwei Cluster-Resourcen auf dem nächsten Node neugestartet: der gemeinsame DRBD-Speicher und der Dienst finch.

Im Cluster-Betrieb kann es, je nach Größe und Applikation, erforderlich sein, sicherzustellen, dass fehlerhafte Nodes an der Wiederaufnahme ihrer Dienste gehindert werden. Dieser Mechanismus wird als STONITH (Shoot the other node in the head) bezeichnet. Es gibt zahlreiche Schnittstellen, um das "Liegenbleiben" des fehlerhaften Clusternodes zu bewerkstelligen, beispielsweise:
- Remote-Interface des Servers (iLO, DRAC, LOM,...)
- USV, an der der Server angeschlossen ist
- PDU (Power Distribution Unit), über welche der Clusternode mit Strom versorgt wird
- Blade-Enclosure Management-Schnittstelle
Wird kein STONITH angewandt, kann es im Extremfall zu Datenkorruptionen kommen, wenn beide Clusternodes (beispielsweise aufgrund eines Netzwerkausfalls) der Meinung sind, der einzig aktive Node zu sein und ihre Applikation ausführen. Implementieren lässt sich STONITH auch unter Linux - unter anderem mit heartbeat oder Pacemaker. In diesem Beispiel würde das jedoch den Rahmen der Übersichtlichkeit sprengen. 😉
Anwendungen lassen sich mit heartbeat sehr einfach im Cluster betreiben, da zur Dienst-Steuerung auf herkömmliche Init-Skripte zurückgegriffen wird. Im Idealfall kann man einfach mit symbolischen Links arbeiten, um einen Dienst in das Cluster zu integrieren.
In diesem Beispiel wird ein benutzerdefiniertes Init-Skript angelegt, welches Finch startet und anschließend den NoIP-Hostname aktualisiert.
Zuerst wird eine clusterweite Konfigurationsdatei (/etc/ha.d/ha.cf) angelegt, in ihr werden grundlegende Parameter, wie Logdateien und Schwellwerte definiert:
1node-a # vi /etc/ha.d/ha.cf
2debugfile /var/log/ha-debug
3logfile /var/log/ha-log
4logfacility local0
5keepalive 10
6deadtime 30
7warntime 20
8initdead 60
9ucast eth0 192.168.2.2
10udpport 694
11auto_failback off
12node hostA.fqdn.dom
13node hostB.fqdn.dom
14
15ESC ZZ
16
17node-b # vi /etc/ha.d/ha.cf
18...
19ucast eth0 192.168.1.2
20...
21
22ESC ZZ
Die Datei unterscheidet sich je Node in einer Zeile (ucast) - hier ist jeweils die IP-Adresse des anderen Nodes einzutragen.
Zu den einzelnen Parametern:
debugfile/logfile/logfacility- Debug-Log und herkömmliches Log; zu verwendende Syslog-Facilitykeepalive- Zeitabstände in Sekunden, in denen Keepalives versendet werdenwarntime- Zeitspanne, ab wann ein Node zu verfallen drohtdeadtime- Zeitspanne, ab wann ein Node tot zu sein scheintinitdead- Zeitpunkt, ab wann ein Node aus dem Cluster entfernt wirducast- IP-Adresse, an welche über Unicast Heartbeat-Pakete versendet werdenudpport- UDP-Portauto_failback- definiert, ob nach Wiedereintritt eines Clusternodes die Ressourcen zurückverschoben werden sollen (sofern dieser Clusternode ein präferierter Node für bestimmte Ressourcen war)node- definiert die vorhandenen Clusternodes nacheinander
Da die Clusterkommunikation verschlüsselt abläuft, muss auf beiden Clusternodes eine Datei unter /etc/ha.d/authkeys angelegt werden:
1both-nodes # vi /etc/ha.d/authkeys
2auth 1
31 sha1 superlangesundsicherespasswort08151337666
Anschließend erfolgt eine Zuteilung der jeweiligen Cluster-Ressourcen - in der Datei /etc/ha.d/haresources:
1both-nodes # vi /etc/ha.d/haresources
2hostA.fqdn.dom
3hostB.fqdn.dom drbddisk::drbd1 Filesystem::/dev/drbd1::/finch::ext4 finch
Die Datei listet zunächst einmal alle Clusternodes und - durch einen Tab abgetrennt - deren primäre Ressourcen auf. In diesem Beispiel gibt es zwei Hosts, wovon der zweite der primäre Clusternode für folgende Ressourcen ist:
- exklusiv verwendetes DRBD-Volume
drbd1 - ext4-Dateisystem auf
/dev/drbd1, welches unter/fincheingehängt wird - Den Dienst
finch(/etc/init.d/finch)
Das bedeutet: sofern beide Clusternodes zur Verfügung stehen, werden die oben genannten Ressourcen immer auf Node 2 (hostB.fqdn.dom) gestartet. Steht der Node nicht zur Verfügung, werden die Ressourcen auf Node 1 (hostA.fqdn.dom) gestartet. Ein automatisches "Zurückverschieben" der Ressourcen erfolgt aufgrund der Einstellung "auto_failback off" (in /etc/ha.d/ha.cf) nicht.
Zuletzt fehlt noch das Initskript zum Starten und Stoppen des Finch-Dienstes - wie bei herkömmlichen Diensten, wird das Skript unter /etc/init.d/finch abgelegt:
1# vi /etc/init.d/finch
2#!/bin/bash
3#
4# finch Startup script for finch including noip update
5#
6
7start() {
8 /usr/local/bin/noip2 -i $(curl --silent http://icanhazip.com) >/dev/null 2>&1
9 chmod g+rw $(tty)
10 su -c "screen -d -m" su-finch
11 RESULT=$?
12 return $RESULT
13}
14stop() {
15 /usr/bin/killall -u su-finch
16 RESULT=$?
17 return $RESULT
18}
19status() {
20 su -c "screen -ls" su-finch
21 cat /proc/drbd
22 dig +short foo.noip.com
23 RESULT=$?
24 return $RESULT
25}
26
27case "$1" in
28 start)
29 start
30 ;;
31 stop)
32 stop
33 ;;
34 status)
35 status
36 ;;
37 *)
38 echo $"Usage: finch {start|stop|status}"
39 exit 1
40esac
41
42exit $RESULT
Das eben erwähnte Initskript kennt die Parameter start, stop und status - und dürfte damit sogar schon fast LSB-kompatibel sein. 🙂
Je nach Parameter wird eine GNU screen-Sitzung unter dem Benutzerkonto von su-finch (Servicebenutzer) gestartet oder beendet - bei der Verwendung des status-Parameters werden aktuelle DRBD- und IP-Zuordnungen inklusive offener Sitzungen angezeigt.
Wenn heartbeat finch-Ressourcen startet oder stoppt, wird dieses Skript verwendet.
Funktionstest
Schön, das war jetzt viel Theorie - doch wie sieht's in der Praxis aus? Funktioniert das überhaupt?
Natürlich - und das zeigt das folgende Beweisvideo am Besten:
😄
Monitoring

Wie es sich für unternehmenskritische Anwendungen gehört, darf ein entsprechendes Monitoring nicht fehlen. Neben der Verfügbarkeit der einzelnen Nodes ist der DRBD- und heartbeat-Status von Interesse. Während sich die Verfügbarkeit des heartbeat-Dienstes kinderleicht mit dem altbekannten check_procs Nagios-/Icinga-Plugins überprüfen lässt, gibt es für DRBD auf der Webseite von MonitoringExchange ein Shell-Skript zum kostenfreien Download: [klick mich!]
Dieses Skript lässt sich ohne Probleme in Nagios bzw. Icinga einbinden und verwenden, hier beispielsweise auf einer passiven Icinga-Instanz:
1# cat /etc/icinga/commands.cfg
2...
3# 'check_drbd' command definition
4define command{
5 command_name check_drbd
6 command_line $USER2$/check_drbd -d $ARG1$ -e "Connected" -o "UpToDate" -w "SyncingAll" -c "Inconsistent"
7}
8
9# cat /etc/icinga/objects/hostA.cfg
10...
11define service{
12 use generic-service
13 host_name hostA
14 service_description HW: drbd1
15 check_command check_drbd!1
16 }
Im oben zu sehenden Beispiel wird überprüft, ob das drbd-Volume /dev/drbd1 zur Verfügung steht. Sofern die Plugin-Antwort (auf Basis der Datei /proc/drbd) nicht "Connected/UpToDate" lautet, liegt ein Fehler vor. Bei aktiver Synchronisation (SyncingAll) wird eine Warnung ausgegeben, ein inkonsistentes Volume (Inconsistent) ergibt einen Fehler.
Fazit
Zweifelsfrei ist dieses Anwendungsbeispiel eher realitätsfern und belustigend. Ich wollte damit zeigen, wie einfach die Implementation von Hochverfügbarkeit unter Linux sein kann. Es gibt viele Wege, die zum Ziel führen - mit heartbeat und DRBD ist hier nur eine von vielen HA-Konstellationen genannt. Die Thematik ist bei weitem nicht so komplex, wie oftmals fälschlicherweise angenommen. Ob nun eine Datenbank oder ein Instant-Messenger über heartbeat "geclustert" wird, ist erstmal irrelevant - der Implementationsaufwand ist überschaubar.
heartbeat gilt eher als veraltetes Tool, mit Pacemaker und OpenAIS/Corosync gibt es zwei modernere Programme, mit denen sich in Kombination mit DRBD weitaus komplexere und umfangreichere HA-Szenarien bewerkstelligen lassen.
Prinzipiell sollte man vor der Implementation von Software HA-Lösungen zuerst die Hardware-Komponenten redundant auslegen - in diesem Beispiel gibt es einige Architekturfehler, die man im Praxisfall idealerweise beheben sollte:
- kein dediziertes Netzwerk für Node-Kommunikation (Heartbeat-Netzwerk)
- kein redundanter Speicher für den Clusterspeicher (RAID-Volume)
- Netzwerkadapter sind nicht redundant gehalten (keine doppelten NICs und entsprechend verbundenen Switches; LACP?)
- keine redundante Stromversorgung
Immerhin wurden hier verschiedene Brandabschnitte gewählt (die Raspberry Pi stehen in zwei verschiedenen Wohnungen)! 🙂
Wer jedoch Interesse daran hat, seinen Instant-Messenger redundant zu halten, weiß ja nun, wie es geht. 😉